
📁 컬렉션 프레임워크
다수의 데이터을 다루기 위한 표준화된 프로그래밍 방식
컬렉션을 다루는 데에 필요한 다양한 클래스들을 제공한다.
컬렉션의 장점
- 배열과 달리 저장하는 크기의 제약이 없다.
- 배열과 달리 객체의 추가, 삽입, 정렬 등 기능 처리가 메서드로 구현되어 있어 간단하게 해결된다.
- 여러 타입의 데이터를 저장할 수 있다.
📁 핵심 인터페이스
📂 Collection
List와 Set의 조상 인터페이스
Collection의 메서드
컬렉션에 저장된 데이터를 읽고 추가/삭제하는 등 기본적인 메서드를 정의하고 있다.
| 메서드 | 설명 |
| boolean add(E element) | 객체를 추가 |
| boolean addAll(Collection c) | 지정된 컬렉션에 포함된 객체를 모두 추가 |
| boolean remove(Object o) | 지정된 객체를 삭제 |
| boolean removeAll(Collection c) | 지정된 컬렉션에 포함된 객체를 모두 삭제 |
| boolean contains(Object o) | 컬렉션에 지정된 객체가 포함되어 있는지 확인 |
| boolean contains(Collection c) | 지정된 컬렉션의 객체들이 포함되어 있는지 확인 |
| boolean retainAll(Collection c) | 지정된 컬렉션에 포함된 객체만을 남기고 삭제 |
| void clear() | 컬렉션의 모든 객체 삭제 |
| boolean isEmpty() | 컬렉션이 비어있는지 확인 |
| boolean equals(Object o) | 동일한 컬렉션인지 비교 |
| int hashCode() | 컬렉션의 해시코드 반환 |
| int size() | 컬렉션에 저장된 객체 수 반환 |
| Iterator iterator() | 컬렉션의 Iterator 인스턴스 반환 |
| Object[] toArray() | 컬렉션을 객체배열로 만들어 반환 |
📂 List
순서가 있는 데이터의 집합. 데이터의 중복 저장이 가능하다.
- ArrayList, LinkedList, Vector, Stack
List의 메서드
리스트는 순서를 가지고 있기 때문에 Collection으로부터 상속받은 메서드 외에도 인덱스와 관련된 메서드가 존재한다.
| 메서드 | 설명 |
| void add(int index, E element) | 지정된 위치에 객체를 추가 |
| void addAll(int index, Collection c) | 지정된 위치에 컬렉션에 포함된 객체를 모두 추가 |
| E get(int index) | 지정된 위치에 있는 객체 반환 |
| int indexOf(Object o) | List를 순방향으로 찾아 지정된 객체의 위치 반환 |
| int lastIndexOf(Object o) | List를 역방향으로 찾아 지정된 객체의 위치 반환 |
| E remove(int index) | 지정된 위치의 객체 삭제 |
| E set(int index, E element) | 지정된 위치에 객체 저장 |
| void sort(Comparator c) | 정렬기준을 이용해 List 정렬 |
| List subList(int from, int to) | 지정된 범위에 있는 객체를 List에 담아 반환 |
📂 Set
순서를 유지하지 않는 데이터의 집합
데이터의 중복을 허용하지 않는다.
- HashSet, TreeSet
📂 Map
순서를 유지하지 않는 데이터의 집합
키(key)와 값(value)의 쌍인 Entry로 저장되며 키의 중복을 허용하지 않는다.
- HashMap, TreeMap
Map.Entry
Map의 내부 인터페이스로 Map에 저장되는 key-value 쌍을 다루기 위해 정의되었다.
Map을 구현하는 클래스는 반드시 Entry 인터페이스도 구현해야 한다.
public interface Map<K,V> {
interface Entry<K,V> { ... }
}Map의 메서드
Map는 List나 Set과 달리 컬렉션의 상속을 받지 않아 따로 메서드를 정의하고 있다.
| 메서드 | 설명 |
| V put(K key, V value) | Map에 key-value 쌍을 저장 |
| void putAll(Map t) | Map의 모든 key-value 쌍을 저장 |
| V remove(Object key) | 지정된 key를 갖는 key-value 객체를 삭제 |
| V get(Object key) | 지정된 key에 대응하는 value를 찾아 반환 |
| void clear() | Map에 저장된 모든 객체를 삭제 |
| boolean isEmpty() | Map이 비어있는지 확인 |
| boolean containsKey(Object key) | 지정된 key와 일치하는 key 객체가 있는지 확인 |
| boolean containsValue(Object value) | 지정된 value와 일치하는 value 객체가 있는지 확인 |
| Set entrySet() | 모든 key-value 객체를 Entry의 Set으로 반환 |
| Set keySet() | 모든 key 객체를 Set으로 반환 |
| Collection values() | 모든 value 객체를 반환 |
Map.Entry의 메서드
Entry는 key와 value에 접근할 수 있는 메서드를 가지고 있다.
| 메서드 | 설명 |
| K getKey() | Entry의 key 객체 반환 |
| V getValue() | Entry의 value 객체 반환 |
| boolean equals() | 동일한 Entry인지 비교. 중복 여부를 판단하는 데에 사용 |
| int hashCode() | Entry의 해시코드 반환. 중복 여부를 판단하는 데에 사용 |
| V setValue(V value) | Entry의 value를 지정된 객체로 변경 |
📁 ArrayList
List를 구현한 클래스로 내부적으로 배열을 사용해서 데이터를 순차적으로 저장하는 컬렉션이다.
기존의 Vector을 개선한 것으로 동기화되어 있지 않다는 점만 제외하면 구현원리와 기능적인 측면에서 동일하다.
ArrayList는 배열 기반 리스트로 내부적으로 배열에 데이터를 저장한다.

- 배열 특성상 모든 데이터가 연속적으로 존재하기 때문에 인덱스를 통한 데이터 접근에 유리하다.
- 크기를 변경할 수 없어 배열이 차면 더 큰 배열을 생성해서 기존의 내용을 복사해야 하므로 처리시간이 길어진다.
- 데이터를 비순차적으로 추가하거나 삭제할 때 다른 요소들의 위치 이동이 필요해 비효율적이다.
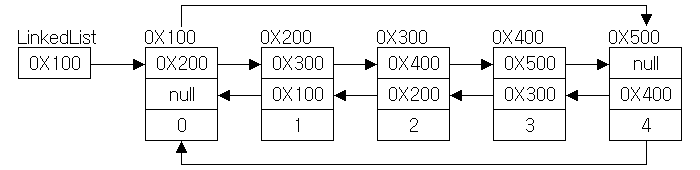
📁 LinkedList
List를 구현한 클래스로 ArrayList의 단점을 보완하기 위해 고안되었다.
불연속적으로 존재하는 데이터들을 서로 연결(link)한 형태로 구성되어 있다.
Node
링크드리스트는 불연속적으로 위치한 요소들을 서로 연결하기 위해 내부적으로 노드(node)를 사용한다.

- Node 클래스는 객체 뿐만 아니라 자신과 연결된 요소에 대한 주소값을 멤버변수로 가지고 있다.
- 다른 요소와 연결할 때에는 기존의 prev, next를 해당 요소의 주소값으로 변경해주면 된다.
public class LinkedList<E> {
class Node {
E element;
Node next;
}
}📂 더블 링크드리스트
단방향 이동만 가능한 링크드리스트의 단점을 보완하여 양방향 이동이 가능한 연결리스트.
링크드리스트는 실제로는 더블 링크드리스트의 형태를 가지고 있다.

📂 더블 써큘러 링크드리스트
더블 링크드리스트에서 접근성을 보다 향상시킨 연결리스트
리스트의 첫번째 요소와 마지막 요소를 연결시켰다.
👊 ArrayList vs LinkedList
- 리스트에 데이터를 순차적으로 추가/삭제할 때에는 연결리스트보다 배열리스트의 성능이 우수하다.
배열리스트는 특정 위치에 대한 접근에 유리하기 때문에 마지막 요소에 빠르게 도달해 작업을 수행할 수 있다. 그러나 연결리스트는 불연속적으로 배치된 요소들이 연결된 것이라 다음 노드의 주소값을 토대로 처음부터 데이터를 따라가야 하는 어려움이 있다.
- 리스트에 데이터를 비순차적으로 추가/삭제할 때에는 배열리스트보다 연결리스트가 성능이 우수하다.
배열리스트에서는 추가할 공간을 마련하거나 빈공간을 채우기 위해 대대적인 요소 재배치가 필요했고, 용량이 부족할 경우 새로운 배열을 생성해주어야 했다. 그러나 연결리스트에서는 단순히 각 요소간의 연결만 변경해주면 되기 때문에 처리속도가 빠르다.
📁 Stack과 Queue
📂 Stack

마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO(Last In First Out) 자료구조.
요소를 순차적으로 추가/삭제하기 때문에 ArrayList와 같은 배열 기반 리스트로 구현할 수 있다.
Stack의 메서드
| 메서드 | 설명 |
| E push(E item) | 스택에 객체를 저장 |
| E pop() | 스택 맨 위에 저장된 객체를 꺼냄. 스택이 비었을 시 EmptyStackException 발생 |
| E peek() | 스택 맨 위에 저장된 객체를 삭제없이 읽어옴 |
| boolean empty() | 스택이 비어있는지 boolean값을 반환 |
| int search(E e) | 스택에서 객체를 찾아 위치를 반환하고 없으면 -1 반환. 인덱스는 1부터 시작 |
📂 Queue

처음에 저장한 데이터를 가장 먼저 꺼내게 되는 FIFO(First In First Out) 자료구조.
처음 저장된 데이터부터 꺼내야 하기 때문에 비순차적인 요소 추가/삭제에 유리한 LinkedList로 구현한다.
Queue의 메서드
| 메서드 | 설명 |
| boolean add(E e) | 큐에 객체를 저장해 성공하면 true 반환. 저장공간이 부족하면 iligalStateException 발생 |
| boolean remove() | 큐에서 객체를 꺼내 반환. 비어있으면 NOSuchElementException 발생 |
| E element() | 큐에서 요소를 삭제없이 읽어옴. 비어있으면 NOSuchElementException 발생 |
| E offer(E e) | 큐에 객체를 저장 |
| E poll() | 큐에서 객체를 꺼내 반환 |
| E peek() | 큐에서 요소를 삭제없이 읽어옴 |
📁 Iterator
컬렉션에 저장된 요소를 접근하는 데에 사용되는 인터페이스
- Collection을 구현한 List와 Set에서만 사용할 수 있다.
- Map에서 사용하기 위해서는 키와 값, 혹은 키와 값의 쌍을 Set으로 얻어온 후 사용해야 한다.
- Set은 순서를 유지하지 않고 데이터를 저장하기 때문에 요소가 저장된 순서와 iterator로 불러온 순서가 다를 수 있다.
Iterator의 메서드
| 메서드 | 설명 |
| Iterator iterator() | Collection에 정의된 메서드로 Iterator 인스턴스를 반환 |
| boolean hasNext() | 읽어올 요소가 남아있는지 확인해 boolean값을 반환 |
| E next() | 다음 요소를 읽어옴. 요소가 없으면 NoSuchElementException 발생 |
| void remove() | next()로 읽어온 요소 삭제. next()를 사용하지 않으면 IllegalStateException 발생. 선택적 구현 |
📂 ListIterator
Iterator을 상속받아 기능을 추가한 것
순차적인 접근만 가능하던 Iterator에서 나아가 양방향으로 요소에 접근할 수 있다.
ListIterator의 메서드
| 메서드 | 설명 |
| ListIterator listIterator() | Collection에 정의된 메서드로 listIterator 인스턴스를 반환 |
| boolean hasPrevious() | 읽어올 이전 요소가 남아있는지 확인해 boolean값을 반환 |
| boolean prevoius | 이전 요소를 읽어옴. 요소가 없으면 NoSuchElementException 발생 |
| int nextIndex() | 다음 요소의 index 반환 |
| int previousIndex() | 이전 요소의 index 반환 |
| void set(E e) | next(), previous()로 읽어온 요소를 지정된 객체로 변환. 선택적 구현 |
📁 Arrays
배열을 다루는 데 유용하게 사용되는 static 메서드들을 정의한 클래스
Arrays의 메서드
| 메서드 | 설명 |
| static String toString | 배열의 요소를 문자열로 출력 |
| static Object[] copyOf(Object[] original, int newLength) | 배열 전체를 복사해서 새로운 배열 반환 |
| static Object[] copyOfRange(Object[] original, int from, int to) | 지정된 범위의 배열을 복사해서 새로운 배열 반환 |
| static void fill(Object[] a, Object val) | 지정된 객체로 배열을 채움 |
| static void sort(Object[] a) | 배열을 정렬 |
| static int binaraySearch(Object[] a, Object key) | 이진검색을 통해 배열에서 주어진 객체를 찾음. 정렬이 선행되어야 함 |
| static List asList(T... a) | 배열을 List로 변환 |
📁 Comparator, Comparable
컬렉션을 정렬하는 데에 사용되는 메서드를 정의한 인터페이스
📂 Comparable
기본적인 정렬기준을 구현하는 데에 사용되는 인터페이스이다.
Integer, Long, String, Date 등의 클래스는 Comparable을 구현해 요소들을 오름차순으로 정렬하도록 하고 있다.
클래스에서 구현하면 정렬 가능한 클래스로 만들어 줄 수 있는데 이때 compareTo()을 오버라이딩해야 한다.
public class Student implements Comparable<Student> {}compareTo()
두 객체를 비교하는 메서드
두 객체가 같으면 0, 비교하는 값보다 작으면 음수, 비교하는 값보다 크면 양수를 반환한다.
// 점수가 낮은 학생부터 높은 학생 순으로 정렬
public int compareTo(Student student) {
return this.score - student.score;
}📂 Comparator
기본 정렬기준이 아닌 다른 기준으로 컬렉션을 정렬하고 싶을 때 사용하는 인터페이스이다.
인터페이스를 구현한 클래스를 만들고 compare()을 오버라이딩해야 한다.
class SortStudent implements Comparator<Student> {}compare()
두 객체를 매개변수로 받아 비교하는 메서드
구현 방법은 compareTo()와 동일하다.
// 점수가 높은 학생부터 낮은 학생 순으로 정렬
public int compare(Student s1, Student s2) {
return s1.compareTo(s2)*(-1);
}
📁 HashSet
Set 인터페이스를 구현한 컬렉션으로 해싱기법을 사용해 객체를 저장한다.
중복 저장을 허용하지 않는데, 저장 여부에 따라 boolean값을 반환하므로 사용에 편리하다.
저장순서를 유지하지 않으므로 중복을 제거하면서 순서를 유지해야 할 경우 LinkedHashSet을 사용해야 한다.
HashSet의 중복 판별
HashSet은 요소를 추가하기 전 기존 요소에 대한 중복을 판단하는데 이때 equals()와 hashCode()를 호출한다.
따라서 저장하려는 객체의 클래스에서알맞게 오버라이딩해주어야 한다.
hashCode()의 오버라이딩 조건
- 동일한 객체에 대해 여러번 호출해도 항상 같은 반환값을 유지해야 한다.
- equals()를 이용한 비교에서 true를 얻은 두 객체의 hashCode() 반환값은 서로 같아야 한다.
- equals()를 이용한 비교에서 false를 얻은 두 객체의 hashCode() 반환값은 되도록 불일치하는 것이 좋다.
📁 TreeSet
Set을 구현한 컬렉션으로 이진검색트리(binary search tree) 자료구조의 형태로 데이터를 저장한다.
데이터를 중복 저장하지 않고 순서를 유지하지도 않는다.
순서를 유지하지는 않지만, 이진트리 특성상 요소를 정렬된 위치에 저장한다.
TreeSet에는 정렬된 요소들을 검색하는 메서드가 다음과 같이 존재한다.
TreeSet의 메서드
| 메서드 | 설명 |
| SortedSet headSet(Object to) | 지정된 객체보다 작은 값들을 반환 |
| SortedSet tailSet(Object from) | 지정된 객체보다 큰 값들을 반환 |
| SortedSet subSet(Object from, Object to) | 범위 검색의 결과를 반환 |
| Object ceiling(Object o) | 지정된 객체와 같은 값을 반환. 없으면 큰 값을 가진 객체 중 가장 가까운 값의 객체 반환. 없으면 null 반환 |
| Object floor(Object o) | 지정된 객체와 같은 값을 반환. 없으면 작은 값을 가진 객체 중 가장 가까운 값의 객체 반환. 없으면 null 반환 |
| Object first() | 정렬된 순서상 첫번째 객체 반환 |
| Object last() | 정렬된 순서상 마지막 객체 반환 |
🤔 이진검색트리
여러개의 노드가 연결된 구조
각 노드에는 최대 2개의 노드를 연결할 수 있으며 연결된 노드들은 상대적으로 부모-자식 관계를 가진다.

- 부모 노드
연결된 노드들 중 상위 노드 - 자식 노드
연결된 노드들 중 하위 노드 - 루트
가장 상위에 있는 노드
이진트리의 노드를 코드로 표현하면 다음과 같다.
class TreeNode {
TreeNode left;
TreeNode Right;
Object element;
}
이진트리에 요소를 저장한다는 것은 트리에서 노드를 연결할 위치를 선택하는 것이다.
왼쪽 노드의 값은 부모 노드보다 작아야 하고 오른쪽 노드의 값은 부모 노드보다 커야 한다.
요소를 넣을 때에는 루트에서부터 출발해 트리에 이미 존재하는 노드들과 값을 비교하며 내려가 최하단에 저장된다.
이처럼 이진트리는 요소의 저장 위치를 탐색하는 과정이 필요하기 때문에 데이터가 많을수록 성능이 떨어진다.
그러나 이미 정렬되어 있기 때문에 특정 요소의 위치나 특정 범위에 속한 요소들을 검색하는 데에 유리하다.
📁 HashMap
Map 인터페이스를 구현한 클래스.
키(key)의 중복은 허용되지 않지만 값(value)는 중복으로 저장될 수 있다.
해싱(hashing)기법을 사용하여 많은 양의 데이터를 검색하는데 있어서 뛰어난 성능을 보인다.
📂 Entry
HashMap은 요소의 key와 value를 묶어서 하나의 쌍으로 저장한다.
내부적으로 Entry 클래스를 정의하고 있으며, 다시 Entry 배열을 선언하고 있다.
key와 해싱
HashMap은 저장하려는 요소의 key에 해싱(hashing)을 적용하여 데이터를 저장한다.
여기서 해싱이란 해시함수를 이용해 데이터를 해시테이블(hashtable)에 저장하고 검색하는 기법을 의미한다.
해시테이블은 다음과 같이 배열과 링크드리스트의 조합으로 이루어져 있다.
배열의 한 요소에는 링크드리스트가 있으며 실제 데이터는 링크드리스트에 저장된다.
배열은 많은 데이터를 나눠서 담기 위한 서랍이라고 생각하면 된다.

배열은 요소들이 연속적으로 배치되어 있어 검색에 유리하지만 링크드리스트는 검색에 불리하다.
배열에 지나치게 큰 링크드리스트가 있다는 것은 서랍에 많은 물건이 있는 것과 같다.
이 경우 검색에 시간이 많이 소요될 수 있으므로 하나의 링크드리스트에는 최소한의 데이터만 저장되게 하는 것이 좋다.
배열의 길이, 즉 서랍의 개수는 해시함수를 어떻게 구현하는지에 따라 정해진다.
테이블에 요소를 넣기 전 key값을 해시함수에 넣기 때문이다.
따라서 검색에 유리한 해시테이블을 만들기 위해서는 해시함수를 적절하게 구현하는 것이 중요하다.
📁 TreeMap
Map을 구현한 컬렉션으로 이진검색트리의 형태로 데이터를 저장한다.
TreeSet과 마찬가지로 검색과 정렬에 적합하지만, 대부분의 경우 HashMap이 검색에 더 유리하다.
TreeMap의 메서드
다음과 같이 정렬과 관련된 메서드가 존재한다.
| 메서드 | 설명 |
| static String toString | 배열의 요소를 문자열로 출력 |
| static Object[] copyOf(Object[] original, int newLength) | 배열 전체를 복사해서 새로운 배열 반환 |
| static Object[] copyOfRange(Object[] original, int from, int to) | 지정된 범위의 배열을 복사해서 새로운 배열 반환 |
| static void fill(Object[] a, Object val) | 지정된 객체로 배열을 채움 |
| static void sort(Object[] a) | 배열을 정렬 |
| static int binaraySearch(Object[] a, Object key) | 이진검색을 통해 배열에서 주어진 객체를 찾음. 정렬이 선행되어야 함 |
| static List asList(T... a) | 배열을 List로 변환 |
📁 Properties
HashMap의 구버전인 HashTable을 상속받아 구현한 것.
키와 값을 모두 String으로 저장하는 보다 단순화된 컬렉션이다.
주로 애플리케이션의 환경설정과 관련된 속성을 저장하는 데에 사용된다.
📁 Collections 클래스
컬렉션을 다루는 데에 필요한 static 메서드들을 제공하는 클래스.
컬렉션의 동기화
멀티쓰레드 프로그래밍에서는 하나의 객체에 여러 쓰레드가 동시에 접근할 수 있다.
데이터의 일관성을 유지하기 위해서는 다음 메서드로 컬렉션을 동기화해어야 한다.
비교적 최근 추가된 컬렉션들은 성능상의 이유로 선택적 동기화를 지원하고 있어 필요할 때 사용하면 된다.
static XXX SynchronizedXXX(XXX x)변경불가 컬렉션
컬렉션을 읽기 전용으로 만들어 저장된 데이터들을 보호해야 하는 경우 사용한다.
static XXX unmodifiableXXX(XXX x)